This project aims at simulating interaction in a virtual environment using Reinforcement Learning and Unity ML-Agents. It was supervised by Dr. Suvranu De, the head of the Department of MANE (Mechanical, Aerospace, and Nuclear Engineering) at Rensselaer Polytechnic Institute and the director of CeMSIM (Center for Modeling, Simulation, and Imaging in Medicine), and Trudi Qi, a researcher at CeMSIM. Although the initial objective of this project was to train a intelligent agent that can catch an throw a given object in a 3D virtual environment, after starting working on the project, it was simplified to an agent that can push a block into a given target from any random location.
Firstly, I did some literature reviews on reinforcement learning, specifically on the differences between reinforcement learning with demonstration and reinforcement learning from scratch. In summary, for reinforcement learning with demonstration, the advantage is that the agent usually has fewer artifacts and is more natural compared with physics-based reinforcement learning from scratch. However, the agent trained by this approach is usually less able to generalize and transfer to other scenarios. Reversely, for agents starting from scratch, it tends to have better flexibility and generality compared with physics-based RL from the demonstration. However, this approach requires a carefully designed reward function, and the agent usually looks unnatural and is easy to cause artifacts under this scenario. There is a tradeoff that exists between specificity and generality.
Then, I started developing the model using reinforcement learning, specifically PPO (Proximal Policy Optimization). Reinforcement learning, by default, is extremely hard to debug since it has too many moving parts, including observations, rewards, and hyperparameters. Therefore, it`s hard to find the problem when the agent does not behave as expected, and it usually requires a tremendous amount of time to tuning and debugging. PPO was proposed to minimize this disadvantage. As an RL algorithm, it finds a point of balance for the difficulty of implementation, tuning, and sample complexity.
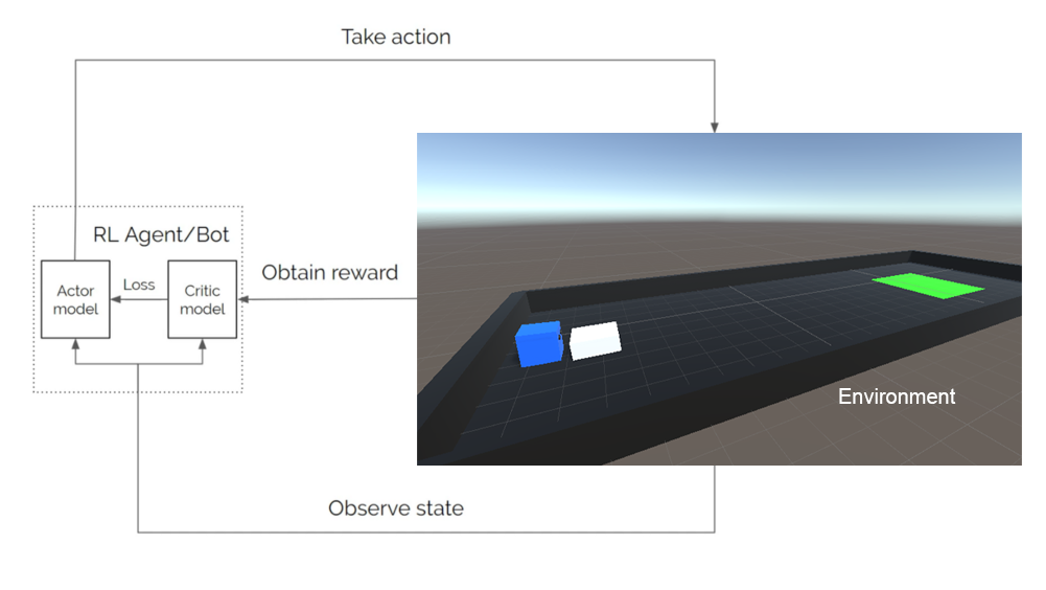
This reinforcement learning algorithm contains two deep neural nets, which are the actor model and the critic model. In every observed state, the agent takes an action, and receive a reward. The agent also enters a new observe state as it takes the action. The actor model is for learning the optimal action under the observed state, whereas the critic model evaluates whether the action can lead to a better state and give feedback to the actor model. In this way, the agent always seeks to maximize the reward.
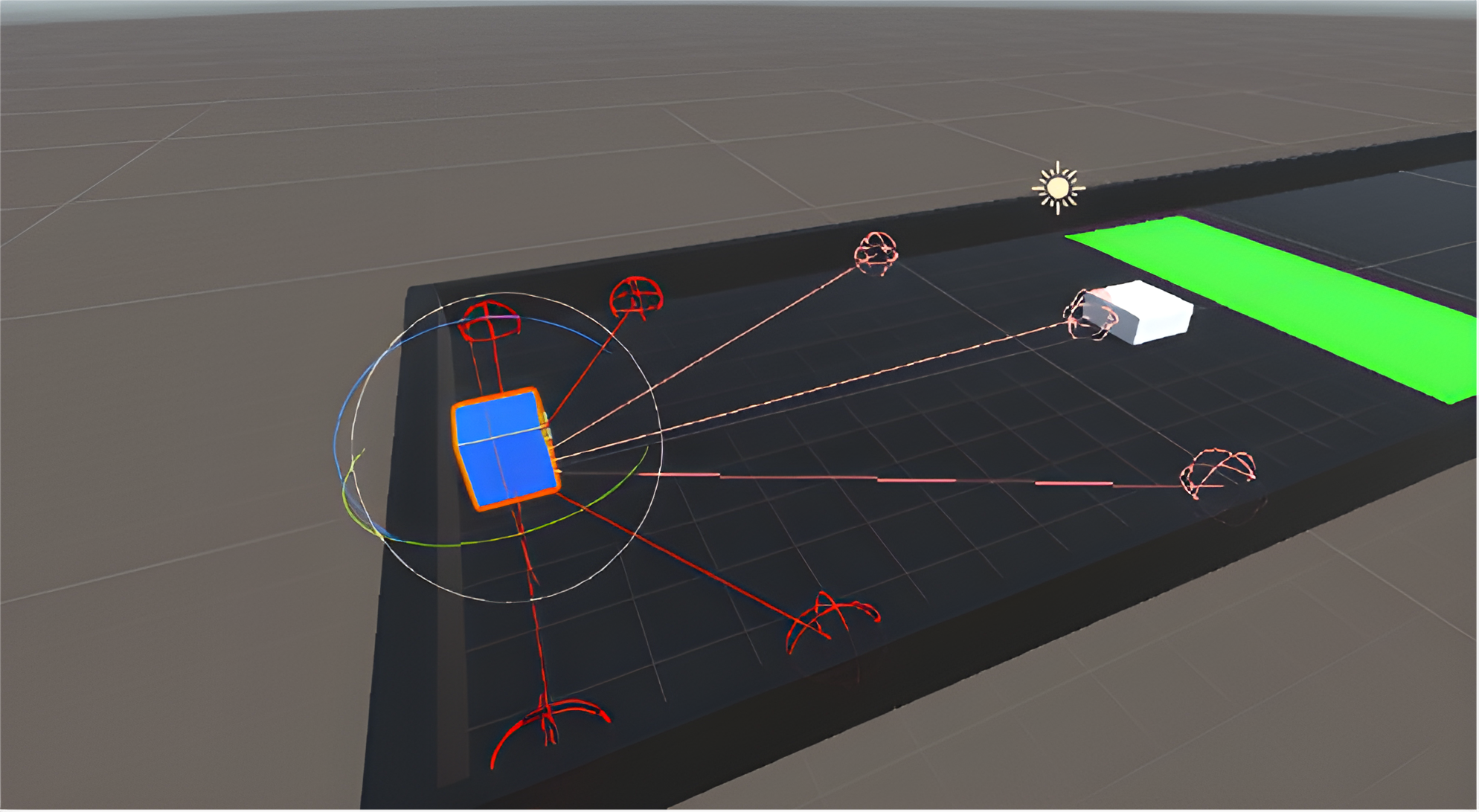
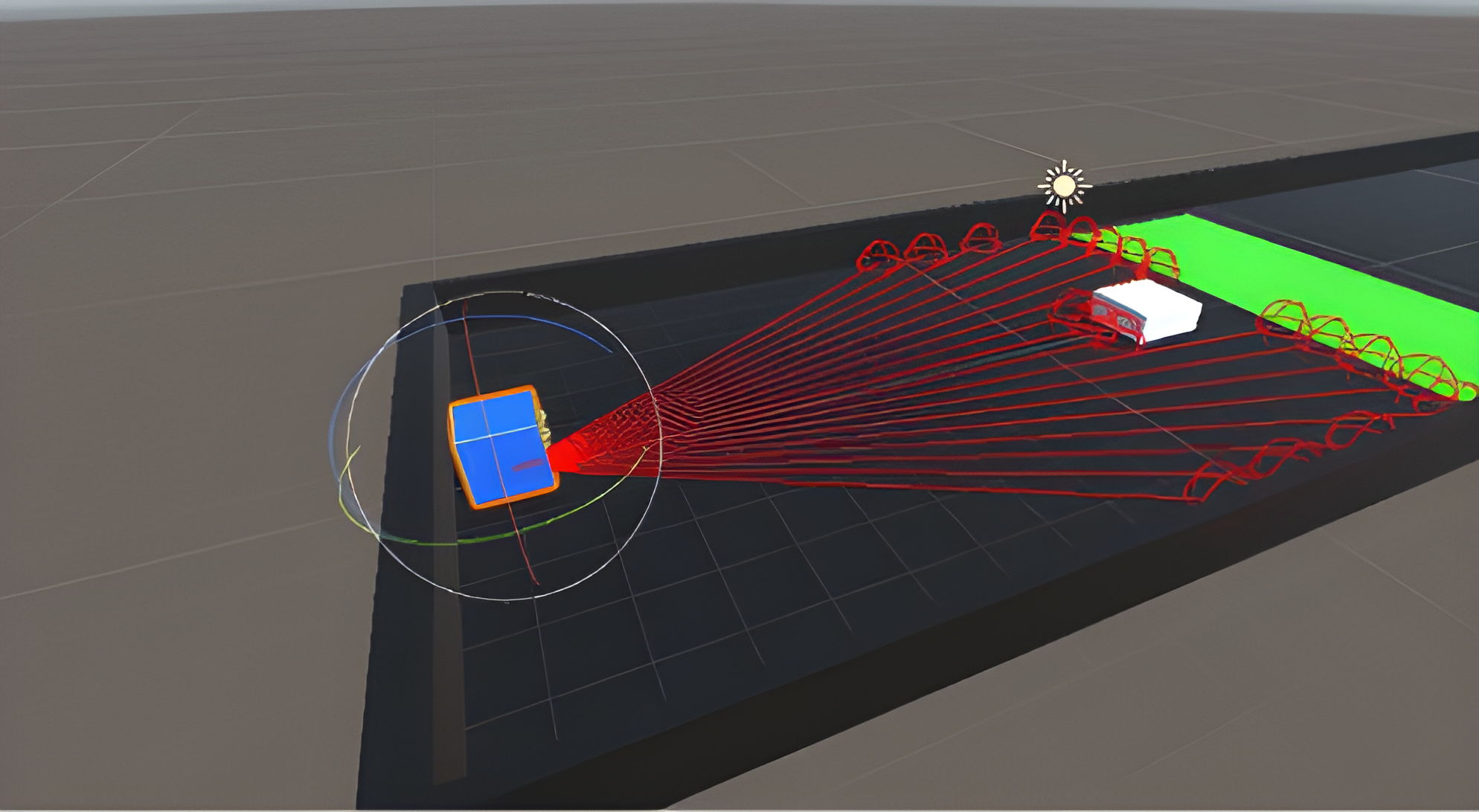
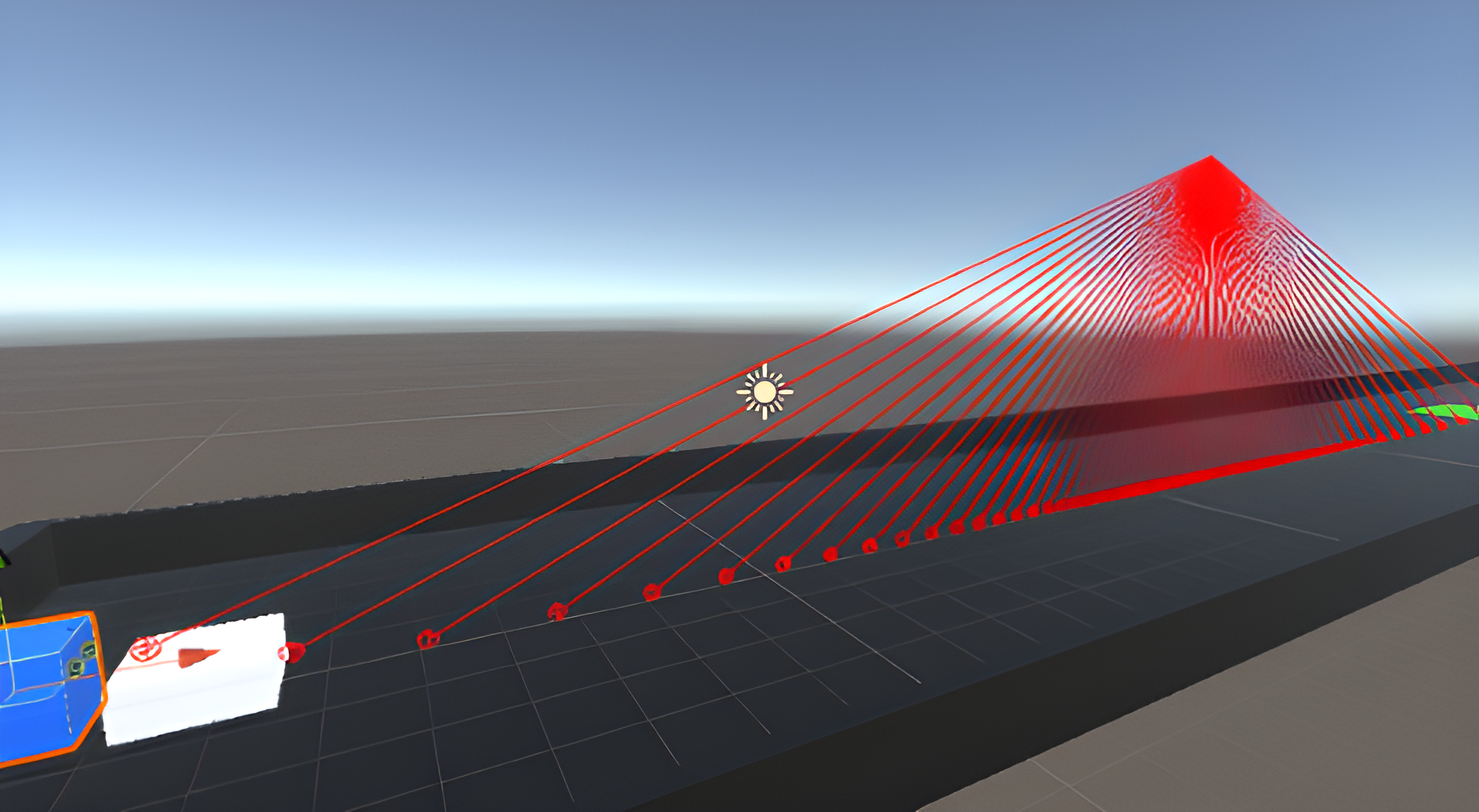
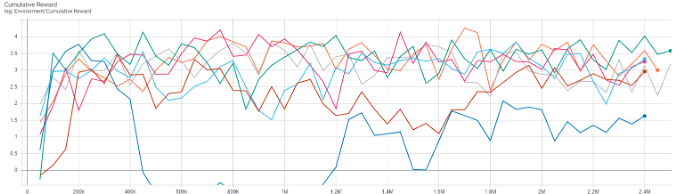
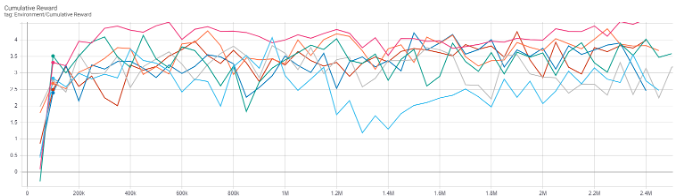
This project was started with discrete action space and changed to continuous action space later. The reward can be set as positive or negative for encouraging desired behavior and discouraging undesired behavior. The agent receives a positive reward every time it successfully scores a goal. The observation can be vector, ray, and camera. In this project, rays and cameras were utilized. Ray perception is using built-in ray casting functionality in Unity to simulate a simplified spatial perception, whereas the camera is using a camera sensor to receive visual input and interpret that using a convolutional neural network. Correct and necessary rewards and observations are important for an agent to complete a given task. Tuning certain PPO-specific hyperparameters are also necessary for leading to the best result.
 |
 |
 |
 |
 |
More detailed information can be found in the source code, presentation slides, and report. The GitHub repository that contains the source code, report and presentation slides of this project can be found here.